
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
Tags
- mongoose
- flask
- react
- Python
- 게임
- cookie
- MySQL
- MongoDB
- OCR
- 정렬
- Bull
- GIT
- Nest.js
- dfs
- typeORM
- Express
- 자료구조
- class
- Queue
- nestjs
- TypeScript
- AWS
- 공룡게임
- Dinosaur
- jest
- nodejs
- game
- Sequelize
- JavaScript
Archives
- Today
- Total
포시코딩
삽입 정렬 (Insertion Sort) 본문
728x90
삽입 정렬
선택 정렬이 전체에서 최솟값을 '선택'하는 정렬이었다면
삽입 정렬은 전체에서 하나씩 올바른 위치에 '삽입'하는 방식이다.
버블 정렬과 선택 정렬은 현재 데이터의 상태와 상관없이 항상 비교하고 위치를 바꿨지만,
삽입 정렬은 필요할 때만 위치를 변경하므로 더 효율적인 방식이라고 할 수 있다.

이번에도 마찬가지로 구해야하는 인덱스의 값부터 for문을 만들어 찾아보자
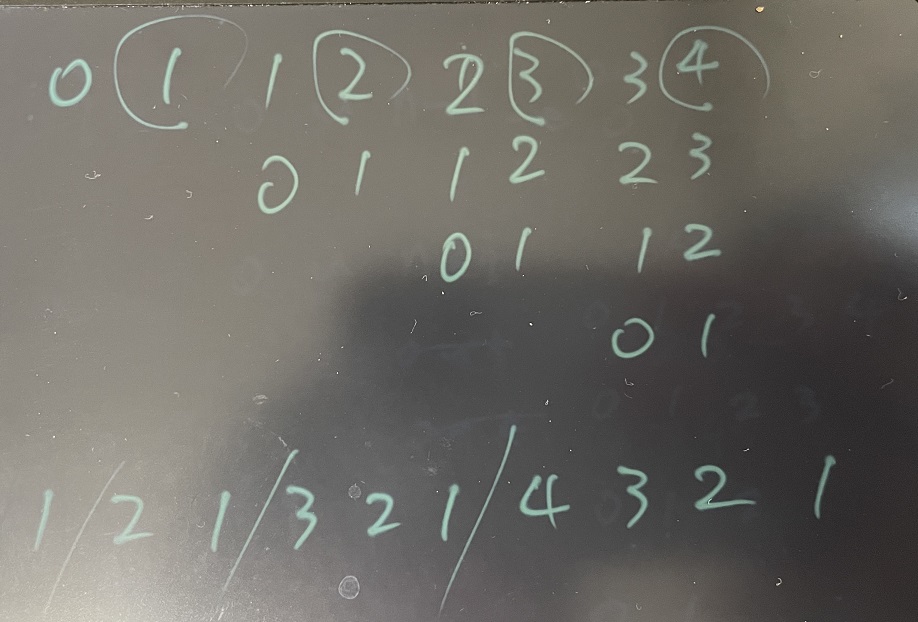
이런식으로 비교할 인덱스가 어떤식으로 전개될지 쭉 써보고
그 중에 i 값은 뭐가 될지 그에 따른 j 값은 뭐가 되고 어떻게 구해야할지 생각해보면
for문을 어떻게 짤지 대충 감이 온다.
arr = [4, 6, 2, 9, 1]
# 1 2 1 3 2 1 4 3 2 1
def insertion_sort(arr):
n = len(arr)
for i in range(1, n): # 1번째 인덱스부터 시작해야 하므로 이와 같이 시작한다.
for j in range(i):
print(i - j)
insertion_sort(arr)이를 통해 삽입 정렬을 구현하면 아래와 같다.
def insertion_sort(arr):
n = len(arr)
for i in range(1, n):
for j in range(i):
val = i-j
if arr[val-1] > arr[val]:
arr[val-1], arr[val] = arr[val], arr[val-1]
else:
break # 오른쪽 값이 더 클 경우 이미 앞에 있는 원소들은 정렬이 되어있으므로
# 더 비교할 이유가 없어 break를 통해 빠져나온다.
return arr
insertion_sort(input)
print(input)
삽입 정렬의 시간 복잡도
삽입 정렬도 O(N2)의 시간 복잡도가 걸린다.
하지만 버블 정렬, 선택 정렬은 최선이든 최악이든 항상 O(N2) 만큼의 시간이 걸리지만
삽입 정렬에서는 최선의 경우 Ω(N) 만큼의 시간 복잡도가 걸리게 된다.
거의 정렬이 된 배열이 들어간다면 break문에 의해서 더 많은 원소와 비교하지 않고 탈출할 수 있기 때문이다.
728x90
'자료구조알고리즘 > 이론' 카테고리의 다른 글
| 스택(Stack) (0) | 2022.11.25 |
|---|---|
| 재귀 함수 응용 (0) | 2022.11.25 |
| 선택 정렬 (Selection Sort) (0) | 2022.11.25 |
| 버블 정렬 (Bubble Sort) (0) | 2022.11.24 |
| 재귀 함수 - 팩토리얼!, 회문 검사 (0) | 2022.11.24 |
'자료구조알고리즘/이론' Related Articles
more


