
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
Tags
- Queue
- react
- TypeScript
- 정렬
- Bull
- flask
- GIT
- MongoDB
- 게임
- OCR
- MySQL
- nestjs
- Express
- jest
- game
- dfs
- class
- JavaScript
- mongoose
- Nest.js
- typeORM
- Dinosaur
- 자료구조
- Python
- nodejs
- cookie
- 공룡게임
- AWS
- Sequelize
Archives
- Today
- Total
포시코딩
[운영체제] 8. Virtual Memory (1) 본문
728x90
키워드
demand paging, page fault, page replacement, optimal algorithm, FIFO algorithm, LRU algorithm, LFU algorithm
Demand Paging
- Demand: 요청이 있으면
- Paging: 그 페이지를 메모리에 올리겠다
- 실제로 필요할 때 page를 메모리에 올리는 것
- I/O 양의 감소
- Memory 사용량 감소
- 빠른 응답 시간
- 더 많은 사용자 수용
- Valid / Invalid bit의 사용
- Invalid의 의미
-> 사용되지 않는 주소 영역인 경우
-> 페이지가 물리적 메모리에 없는 경우 - 처음에는 모든 page entry가 invalid로 초기화
- address translation 시에 invalid bit이 set되어 있으면
-> page fault
- Invalid의 의미

- 1번 페이지에 대해 CPU가 접근을 위해 주소 변환하려고 봤더니 invalid일 경우
-> 해당 페이지가 메모리에 존재하지 않음 - 해당 페이지를 디스크에서 메모리로 올림 -> I/O 작업
(사용자 프로세스가 직접 하지 못함) => page fault 현상 발생
Page Fault

- 요청한 페이지가 메모리에 없는 경우 page fault가 났다. 라고 표현한다.
- invalid page를 접근하면 MMU가 trap을 발생시킴 (page fault trap), 일종의 software interrupt
-> CPU는 자동적으로 운영체제에 넘어가게 된다. - Kernel mode로 들어가서 page fault handler가 invoke됨
- 다음과 같은 순서로 page fault 처리
- Invalid reference?
-> 잘못된 요청이 아닌지 체크
ex) bad address, protection violation => abort process - Get an empty page frame. (없으면 뺏어옴: replace)
- 해당 페이지를 disk에서 memory로 읽어온다.
- Disk I/O가 끝나기까지 이 프로세스는 CPU를 preempt 당함 (block)
- Disk read가 끝나면 page tables entry 기록, valid/invalid bit = "valid"
- ready queue에 process를 insert -> dispatch later
- 이 프로세스가 CPU를 잡고 다시 running
- 아까 중단되었던 instruction 재개
- Invalid reference?
Performance of Demand Paging

- page fault가 얼마냐 나느냐에 따라 메모리 접근 시간이 크게 좌우됨
- page fault의 비율을 0에서 1 사이 값으로 볼 때
- 0일 경우: page fault가 발생하지 않음. 메모리에서 다 참조가 된다.
- 1일 경우: 매번 메모리 참조할 때마다 page fault 발생
- 실제로 계산해보면 page fault의 비율은 0에 가까움
- 때문에 대부분의 경우에는 page fault가 나지 않고 메모리로부터 직접 주소 변환을 할 수 있고
메모리에 올라와 있지 않은 특별한 경우에 page fault가 나서 disk 접근이 필요하게 된다. - page fault가 난다면 아래 과정이 소요됨
- 운영체제로 CPU가 넘어와서 하드웨어로 page fault를 처리하는 오버헤드
- 메모리에 빈 공간이 없으면 페이지 하나를 쫓아냄
- 빈 자리에 disk에서 읽어온 page를 올림
- 운영체제가 page table에 valid로 표시 및 나중에 CPU 얻으면 restart
Free frame이 없는 경우
Page replacement
- 메모리에 빈 페이지가 없는 경우 뭔가를 쫓아내는 것을 의미
- 어떤 frame을 빼앗아올지 결정해야 함
- 곧바로 사용되지 않을 page를 쫓아내는 것이 좋다.
- 동일한 페이지가 여러 번 메모리에서 쫓겨났다가 다시 들어올 수 있음
Replacement Algorithm
- page-fault rate를 최소화하는 것이 목표
-> 0에 가깝도록 - 알고리즘의 평가
-> 주어진 page reference string에 대해 page fault를 얼마나 내는지 조사 - reference string의 예
-> 1, 2, 3, 4, 1, 2, 5, 1, 2, 3, 4, 5

- disk에서 memory로 올라온 이후에 내용이 변경됐다고 하면
즉, write가 발생했다고 하면 쫓아낼 때 변경된 내용을 memory에서 backing store에 써줘야 함 - 하지만, 그동안 변경된게 없다면 지워버리면 된다.
Optimal Algorithm
(=Belady's optimal algorithm, MIN, OPT 등)

- page fault를 가장 적게 하는 알고리즘
- 실제 시스템에서는 미래를 알 수 없지만 optimal algorithm은 미래에 참조되는 page들을 미리 다 안다고 가정
-> 실제 시스템에 사용은 못하니 Offline algorithm이라 함. - 아무리 좋은 알고리즘을 만들어도 optimal algorithm보다 성능이 좋을 수 없음
-> 이 말은 만약 새로 만든 알고리즘 성능이 optimal algorithm이랑 비슷할 경우
더 이상 좋은 알고리즘을 만들 수 없다는 얘기이므로 참고 기준으로 사용됨
FIFO Algorithm
(First In First Out)

- 실제 시스템에서 사용 가능한, 미래를 모르는 상태에서 운영하는 알고리즘
- 사진은 memory에 page가 3개 있는 경우와 4개 있는 경우로 나눈 예시
- 특이하게 memory 크기를 3 page frame에서 4 page frame으로 늘렸을 때
보통은 성능이 좋아져야 하는데 page fault가 늘어나 성능이 더 나빠지는걸 볼 수 있다.
-> FIFO Anomaly(=Belady's Anomaly)
LRU Algorithm
(Least Recently Used)

- 가장 덜 최근에 사용된(가장 오래된) page를 쫓아냄
- 먼저 들어왔지만 들어온 다음 재사용되지 않은 가장 오래된 것을 쫓아낸다는 점이 FIFO와 다르다.
- 최근에 참조된 page가 가까운 미래에 다시 참조될 가능성이 높은 성질을 이용
LFU Algorithm
(Least Frequently Used)
- 가장 덜 빈번하게 사용된 page를 쫓아냄
- 참조 횟수(빈도)(reference count)가 가장 적은 페이지를 지움
- 최저 참조 횟수인 page가 여럿 있는 경우
- 어떤걸 쫓아낼지 딱히 명시하고 있진 않다.
LFU algorithm 자체에서는 여러 page 중 임의로 선정한다. - 성능 향상을 위해 가장 오래 전에 참조된 page를 지우게 구현할 수도 있다.
- 어떤걸 쫓아낼지 딱히 명시하고 있진 않다.
- 장점
- LRU처럼 직전 참조 시점만 보는 것이 아닌 장기적인 시간 규모를 보기 때문에
page의 인기도를 좀 더 정확히 반영할 수 있음
- LRU처럼 직전 참조 시점만 보는 것이 아닌 장기적인 시간 규모를 보기 때문에
- 단점
- 참조 시점의 최근성을 반영하지 못함
- LRU보다 구현이 복잡함
LRU와 LFU 알고리즘 예제

- LRU algorithm은 마지막 참조 시점만 보기 때문에
그 이전에 어떤 기록을 가지고 있는지 생각하지 않는다는게 약점 - 가장 오래전에 참조되긴 했지만 그때부터 굉장히 많은 참조가 과거에 있었다는 사실을
LRU는 전혀 고려하지 않음 - 반대로 LFU algorithm은 비록 4번이 참조 횟수가 한 번이지만 이제 막 참조가 시작되는 상황이라 문제 발생
-> 이제부터 계속 참조하게 될 page가 될 수도 있으니까 - 이러한 두 알고리즘의 장단점을 보완하는 page raplacement algorithm에 대해서는
20년이 넘게 많은 연구와 개발이 진행중
LRU와 LFU 알고리즘의 구현
LRU Algorithm

- memory 안에 있는 page들을 참조 시간 순서에 따라 한줄로 줄세우기를 함
- 맨 위가 가장 오래되고 아래로 갈수록 최근
- LinkedList 형태로 운영체제가 관리
- 어떤 page가 memory에 들어오거나 memory 안에서 다시 참조될 경우
참조 시점이 가장 최근이 되어 제일 아래로 이동 - 쫓아낼 때는 제일 위에 있는 것을 쫓아내면 됨
-> 쫓아내기 위해 비교가 필요 없음 - 시간복잡도: O(1)
LFU Algorithm
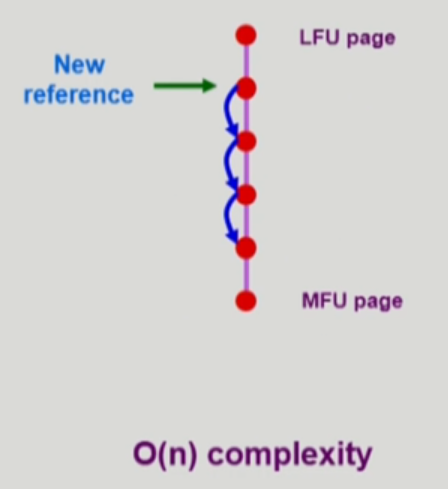
- 가장 참조 횟수가 적은 page가 맨 위, 참조 횟수가 많은 page가 아래로 위치하게
한 줄로 줄세우기를 하면 될 것 같지만 줄세우기를 할 수 없다.
-> 어떤 page가 참조됐을 때 LRU는 한번만 참조되도 지금 참조된 page가 제일 가치가 높아짐
반면, LFU에서는 참조되어도 참조 횟수가 1이 늘어난 것일 뿐, 가장 참조 횟수가 많은 page가 되지 않는다. - 비교를 통해 어디까지 내려갈 수 있는지 확인이 필요
- 최악의 경우, 참조된 page 아래로 참조 횟수가 모두 같아 한 번에 참조로 인해 제일 아래로 내려가야 되는데
그냥 내려가는게 아닌 하나하나 비교해서 어디까지 내려갈 수 있는지 체크하며 내려가야 함 - 위의 경우 시간복잡도: O(n)

- 위와 같은 이유로 LFU algorithm은 heap을 통해 구현한다.
- 자식이 두 개씩 있는 이진 트리 형태
- 맨 위는 참조 횟수가 제일 적은 page, 밑으로 갈수록 참조 횟수가 더 많은 page
- 어떤 page가 참조되면 직계 자식 두개하고만 비교하여 자리 바꿈
-> 자식 둘 보다 참조 횟수가 많지 않은 경우까지 반복 - 이를 통해 비교 횟수가 많아봐야 O(log n)이 된다.
- 쫓아낼 때 root를 쫓아내고 heap을 재구성
다양한 캐싱 환경
캐싱 기법
- 한정된 빠른 공간(=캐시)에 요청된 데이터를 저장해두었다가 후속 요청 시 캐시로부터 직접 서비스하는 방식
- paging system 외에도 cache memory, buffer caching, web caching 등 다양한 분야에서 사용
캐시 운영의 시간 제약
- 교체 알고리즘에서 삭제할 항목을 결정하는 일에 지나치게 많은 시간이 걸리는 경우 실제 시스템에서 사용할 수 없음
- Buffer caching이나 web caching의 경우
- O(1)에서 O(log n) 정도까지 허용
- Paging system인 경우
- page fault인 경우에만 OS가 관여
- 페이지가 이미 메모리에 존재하는 경우 참조시각 등의 정보를 OS가 알 수 없음
- O(1)인 LRU의 list 조작조차 불가능
728x90
'CS (Computer Science)' 카테고리의 다른 글
| [운영체제] 9. File Systems (1) (0) | 2023.05.25 |
|---|---|
| [운영체제] 8. Virtual Memory (2) (0) | 2023.05.23 |
| [운영체제] 7. Memory Management (5) - 정리 (0) | 2023.05.17 |
| [운영체제] 7. Memory Management (4) (0) | 2023.05.17 |
| [운영체제] 7. Memory Management (3) (0) | 2023.05.17 |
'CS (Computer Science)' Related Articles
more


