
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
Tags
- 자료구조
- TypeScript
- 공룡게임
- typeORM
- dfs
- GIT
- nodejs
- 정렬
- class
- 게임
- Express
- Nest.js
- AWS
- OCR
- mongoose
- Python
- cookie
- Bull
- MySQL
- react
- Dinosaur
- JavaScript
- Queue
- flask
- MongoDB
- game
- Sequelize
- jest
- nestjs
Archives
- Today
- Total
포시코딩
Array(어레이), Linked List(링크드리스트) 본문
728x90
개요
들어가기에 앞서, 자료구조를 왜 배워야할까?
특정 자료구조는 삽입/삭제가 빠르고
특정 자료구조는 조회가 빠르다.
이처럼, 어떤 경우에는 이 자료구조가 좋고, 어떤 경우에는 저 자료구조가 좋은 것 처럼
경우에 따라 다양한 자료구조와 알고리즘을 사용해야 한다.
이번 포스팅에선 자료구조 중 Array와 Linked list에 대해 알아보도록 하자
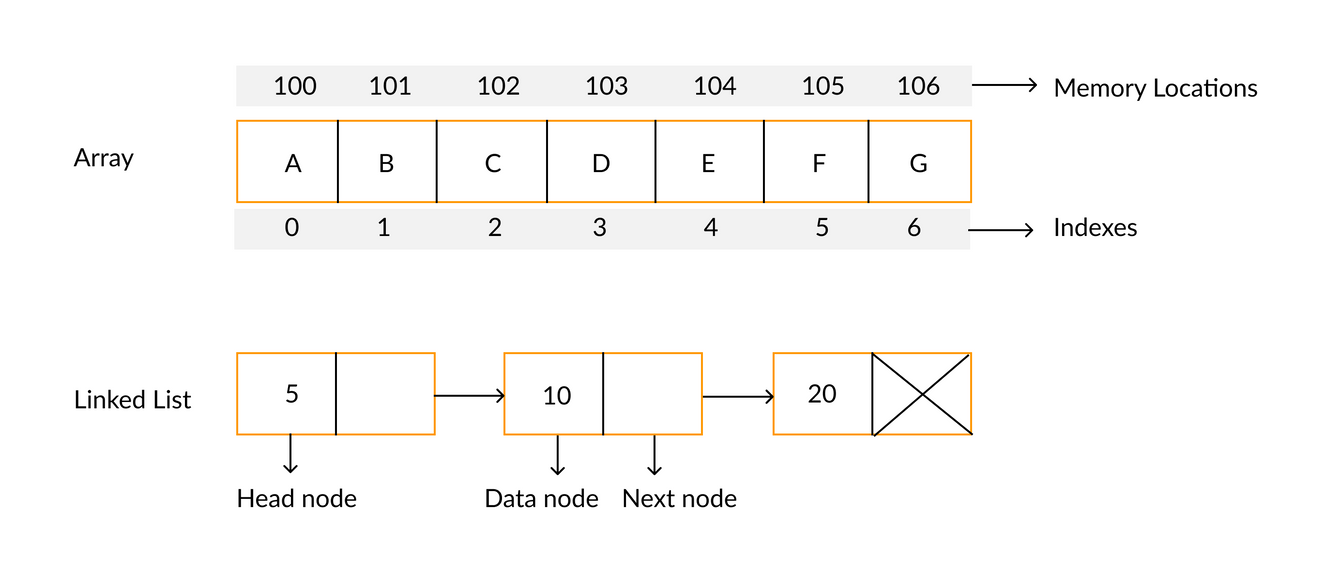
특징
어레이(Array) = 배열
- 배열은 크기가 정해진 데이터의 공간이다. 한 번 정해지면 바꿀 수 없음
- 배열은 각 원소에 즉시 접근할 수 있다. ex) arr[0]
여기서 원소의 순서는 0부터 시작하고 이를 인덱스라고 부른다.
이 때, 즉시 접근 가능하다는 말은 상수 시간 내에 접근할 수 있음을 의미한다.
즉, O(1) 내에 접근 할 수 있다고 말할 수 있다. - 배열은 원소를 중간에 삽입/삭제 하려면 모든 원소를 다 옮겨야 한다.
최악의 경우 배열의 길이 N 만큼을 옮겨야 하므로 O(N)의 시간 복잡도를 가진다. - 원소를 새로 추가하려면, 새로운 공간을 할당해야 하므로 매우 비효율적인 자료구조이다.
- 조회
- O(1)의 조회시간을 가진다는 매우 큰 장점이 있다.
- 여기서 O(1)이란 무조건 한 번에 상수적으로 값을 조회할 수 있다는 얘기.
인덱스 값을 받으면 해당하는 배열의 값을 바로 리턴하기 때문
- 삽입 & 삭제
- 배열 끝에서 추가 및 삭제는 O(1)이다.
- 배열 끝이 아닌 다른 곳에서 원소를 삽입 혹은 삭제 할 경우에는 O(N)이다.
- 삽입 & 삭제 시 새로 배정될 배열을 생성하고 특정 배열을 넣거나 빠진 상태로 재정렬(재배치)하기 때문에
시간 복잡도가 O(N)이 된다. 재배치를 안하면 삭제 시 NULL 값들이 마구마구 생기게 될 것이다.
- 삽입 & 삭제 시 새로 배정될 배열을 생성하고 특정 배열을 넣거나 빠진 상태로 재정렬(재배치)하기 때문에
- 정렬
- 정렬의 경우엔 어떤 정렬 알고리즘을 사용하느냐에 따라 시간 복잡도가 다 다르게 나온다.
- 검색
- 일반적으로 O(N)이다. 첫 원소부터 끝 원소까지 다 봐야하니까
- 정렬이 되어있는 배열이면 O(log N)이 가능하다. (base가 2인 log) -> 2진 탐색을 통해
링크드 리스트(Linked list) = 리스트
- 리스트는 크기가 정해지지 않은 데이터의 공간이다.
연결 고리로 이어주기만 하면 자유자재로 늘어남 - 리스트는 특정 원소에 접근하려면 연결 고리를 따라 탐색해야 한다.
최악의 경우에는 모든 요소를 탐색해야 하므로 O(N)의 시간 복잡도를 가진다. - 연결 고리를 포인터, 각 요소를 노드라고 부른다.
- 리스트는 원소를 중간에 삽입/삭제 하기 위해서 앞 뒤의 포인터만 변경하면 된다.
따라서 원소 삽입/삭제를 O(1)의 시간 복잡도 안에 할 수 있다.
정리
| 경우 | Array | LinkedList |
| 특정 원소 조회 | O(1) | O(N) |
| 중간에 삽입 / 삭제 | O(N) | O(1) |
| 데이터 추가 | 데이터 추가 시 모든 공간이 다 차버렸다면 새로운 메모리 공간을 할당받아야 한다. | 모든 공간이 다 찼어도 맨 뒤의 노드만 동적으로 추가하면 된다. |
| 정리 | 데이터에 접근하는 경우가 빈번하다면 Array 사용 |
삽입과 삭제가 빈번하다면 LinkedList 사용 |
Python에서 리스트(list)를 통해 배열 활용하기
- A.append(6): 맨 뒤에 6을 삽입
- A.pop(): 맨 뒤의 값을 지우고 리턴
- A.pop(1): A[1]을 제거하고 리턴. 지운 자리는 왼쪽으로 한 칸씩 땡겨 채우게 된다.
- A.insert(1, 10): A[1]에 10을 삽입. 넣은 자리부터 오른쪽으로 한 칸씩 밀리게 된다.
- A.remove(value): A에서 value 제거
- A.index(value): 왼쪽부터 시작해서 처음으로 등장하는 value값의 index 값 리턴
- A.count(value): value값의 등장 횟수 리턴
728x90
'자료구조알고리즘 > 이론' 카테고리의 다른 글
| 재귀 함수 - 팩토리얼!, 회문 검사 (0) | 2022.11.24 |
|---|---|
| 이진 탐색(Binary Search), 시간 복잡도 O(log N) (0) | 2022.11.24 |
| Linked List 구현 using class in Python (2) (0) | 2022.11.23 |
| Linked List 구현 using class in Python (1) (0) | 2022.11.23 |
| 시간복잡도의 점근 표기법 (Big-O, Big-Ω) (0) | 2022.11.22 |
'자료구조알고리즘/이론' Related Articles
more

