
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- Bull
- mongoose
- class
- OCR
- 정렬
- nodejs
- 공룡게임
- cookie
- JavaScript
- Python
- game
- nestjs
- flask
- Sequelize
- dfs
- typeORM
- AWS
- MySQL
- Nest.js
- react
- 자료구조
- 게임
- jest
- Dinosaur
- GIT
- Queue
- TypeScript
- MongoDB
- Express
- Today
- Total
포시코딩
[MST][최소 신장 트리] Kruskal's algorithm 본문
크루스칼 알고리즘(Kruskal's algorithm)
탐욕 알고리즘을 기반으로 한다.
- 모든 정점을 독립적인 집합으로 만든다.
- 모든 간선을 비용(가중치)을 기준으로 정렬하고, 비용이 작은 간선부터 양 끝의 두 정점을 비교한다.
- 두 정점의 최상위 정점을 확인하고, 서로 다를 경우 두 정점을 연결한다. (사이클이 생기지 않도록)
간단히 말해서, 모든 정점을 리스트로 만든 후 비용이 적은 간선부터 하나씩 연결하되 사이클이 생기지 않게 하면 된다.
언제까지? 모든 노드들이 연결될 때까지
과정
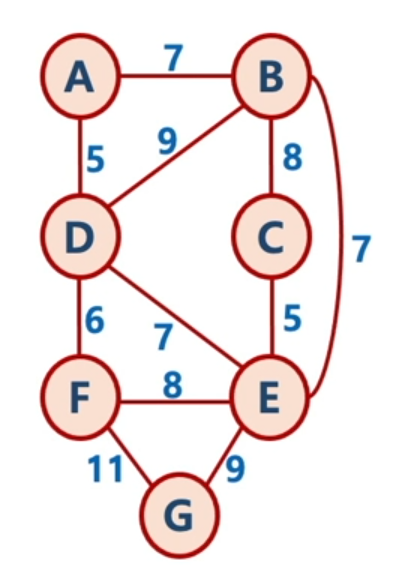
아래와 같은 그래프가 있다고 가정할 때, 크루스칼 알고리즘으로 최소 신장 트리를 구하는 과정에 대해 알아보자

1. 가장 가중치가 작은 간선은 5의 가중치를 가진 A-D, C-E가 있다. 뭘 먼저 선택하든 상관없지만 우선 A-D를 연결한다.
2. 그 이후 마찬가지로 가장 작은 5의 가중치를 가진 C-E를 연결한다.
3. 다음으로 작은 간선의 가중치인 6을 가진 D-F를 연결한다.
4. 그 다음 가중치인 7을 가진 A-B 연결
5. 마찬가지 7을 가진 B-E 연결
6. 아직 가중치 7을 가진 D-E와 8, 9의 가중치를 가진 애들이 남았지만 이후 아래에 나올 이유들로 일단 패스
그 중 9의 가중치를 가진 G-E를 연결한다.
7. 이렇게 최소한의 비용으로 모든 노드를 연결한 것을 볼 수 있다.
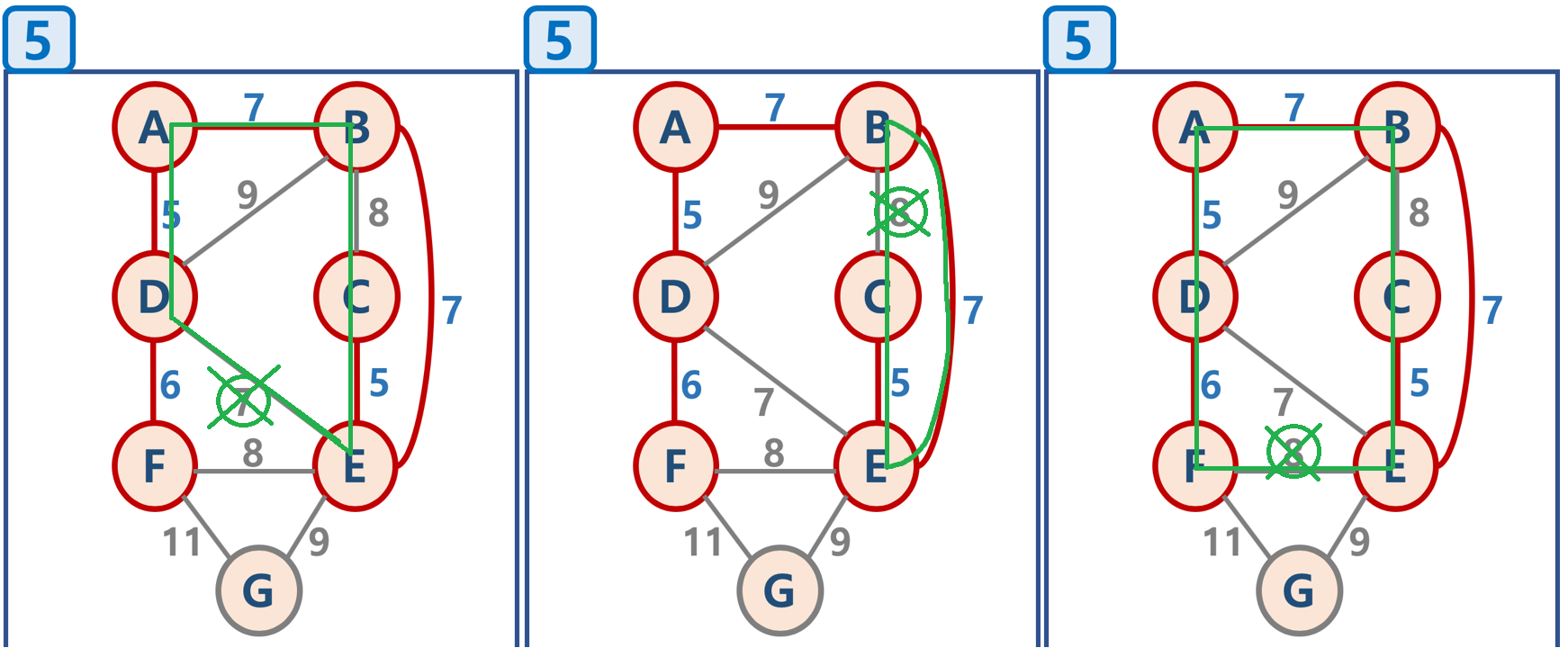
5-1. 5번 순서에서 7의 가중치를 가진 D-E를 연결할 때, 사이클이 생기기 때문에 D-E는 연결될 수 없다.
마찬가지로 B-C, F-E도 그림과 같이 사이클이 생기기 때문에 연결할 수 없음
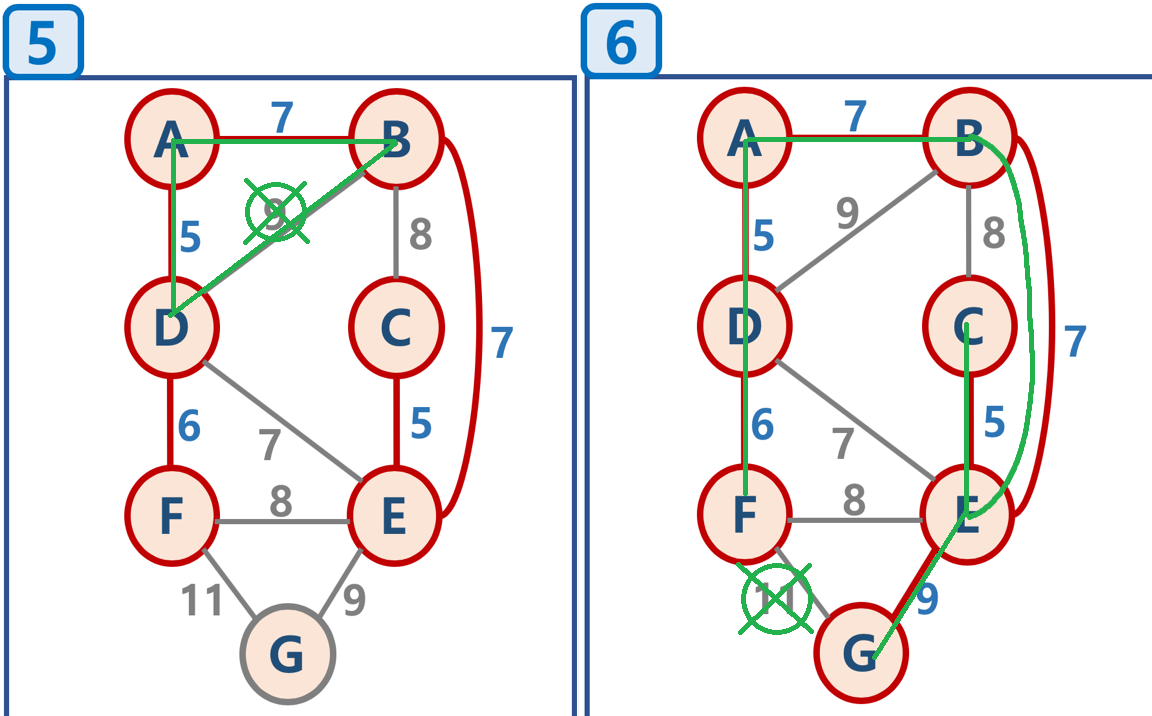
5-2. 9의 가중치를 가진 B-D도 사이클이 생기기 때문에 연결할 수 없으며
6-1. 가중치 11을 가진 F-G는 이미 가중치 9의 G-E가 연결되며 모든 노드가 연결되었기 때문에 더 이상 연결될 필요가 없어져 생략된다.
Union-Find 알고리즘
- 크루스칼 알고리즘에서뿐만이 아닌 Disjoint Set을 표현할 때 사용하는 알고리즘으로
트리 구조를 활용하는 알고리즘이다. - 노드들 중에 연결된 노드를 찾거나 노드들을 서로 연결할 때(합칠 때) 사용한다.
- 크루스칼 알고리즘에선 사이클이 생기는지를 체크하는 용도로 사용한다.
* Disjoint Set?
- 서로 중복되지 않는 부분 집합들로 나눠진 원소들에 대한 정보를 저장하고 조작하는 자료구조
- 공통 원소가 없는(서로소) 상호 배타적인 부분 집합들로 나눠진 원소들에 대한 자료구조를 의미
- 즉, Disjoint Set = 서로소 집합 자료구조
초기화
- n개의 원소가 개별 집합으로 이루어지도록 초기화한다.

Union
- 두 개별 집합을 하나의 집합으로 합친다. (두 트리를 하나의 트리로)
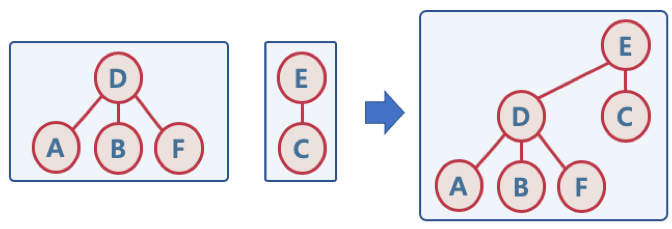
Find
- 사이클을 체크하는 기능
- 두 노드가 연결될 때, 각 노드의 루트 노드를 확인한다.
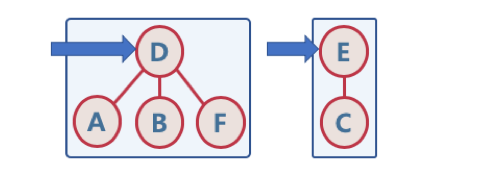
고려할 점
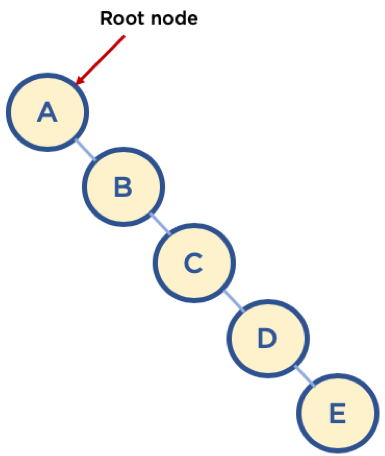
- Union 순서에 따라, 최악의 경우 링크드 리스트와 같은 형태가 될 수 있다.
- 이 때는 union/find 시 계산량이 O(N)이 될 수 있으므로,
해당 문제를 해결하기 위해 union-by-rank, path compression 기법을 사용한다.
union-by-rank 기법
- 두 부분집합이 합쳐질 때, 어떻게 하면 높이를 작게 하냐에 초점을 맞춤
- 각 트리에 대해 높이(rank)를 기억해두고, union 시 두 트리의 높이가 다르면
높이가 작은 트리를 높이가 큰 트리에 붙인다.
(즉, 높이가 큰 트리의 루트 노드가 합친 집합의 루트 노드가 되게)
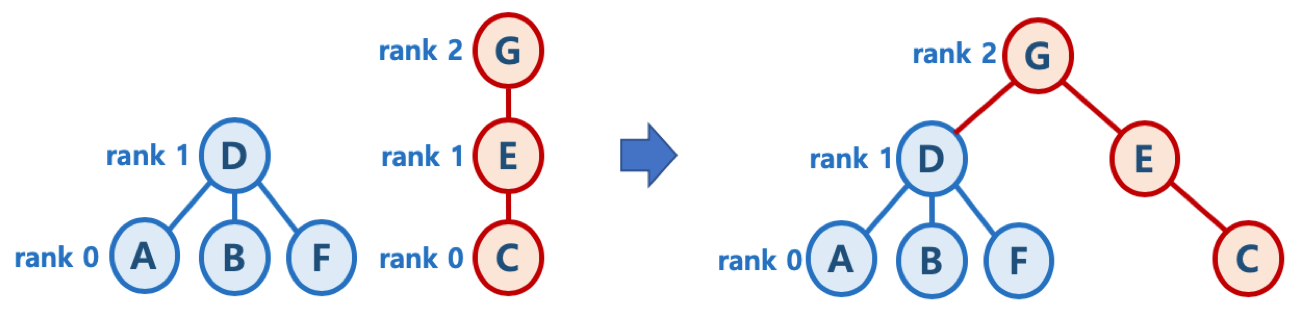
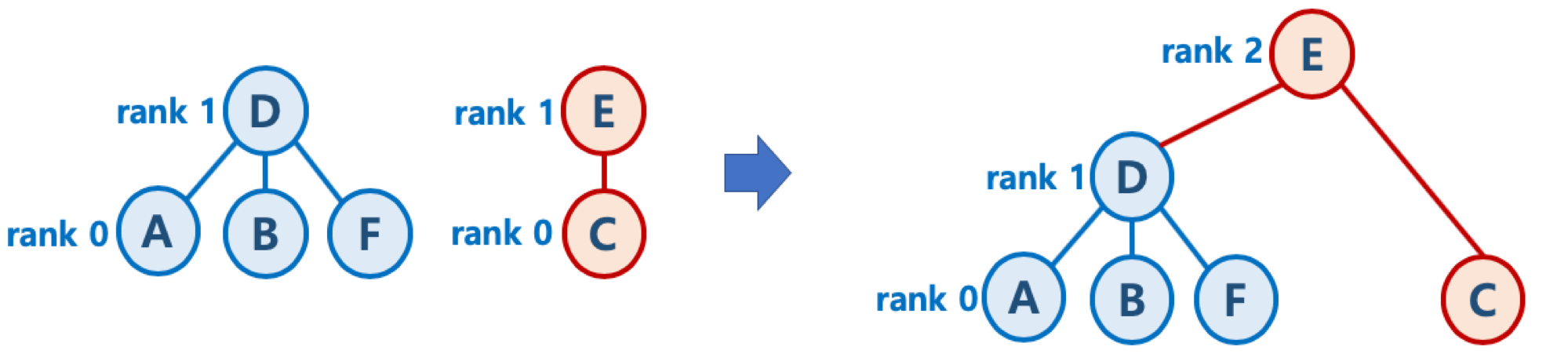
- 높이가 h - 1인 두 개의 트리를 합칠 때(즉, 높이가 같을 때)는
한 쪽의 루트 노드의 높이(rank)값만 1 증가시킨 후, 다른 쪽의 트리를 해당 트리에 붙인다.
- 초기화 시, 모든 원소는 높이(rank)가 0인 개별 집합 상태에서 -> 하나씩 원소를 합칠 때 union-by-rank 기법을 사용한다면
- 높이가 h인 트리가 만들어지려면, 높이가 h - 1인 두 개의 트리가 합쳐져야 한다.
- 높이가 h - 1인 트리를 만들기 위해 최소 n개의 원소가 필요하다면,
높이가 h인 트리가 만들어지기 위해 최소 2n개의 원소가 필요하다. - 따라서 union-by-rank 기법을 사용하면,
union/find 연산의 시간복잡도는 O(N)이 아닌 O(logN)으로 낮출 수 있다.
* 더 자세한 내용은 아래 영상 참고
path compression(경로 압축) 기법
- Find를 실행할 때 동작. (* Find는 루트 노드를 찾는 행위)
- Find를 실행한 노드에서 거쳐간 노드를 루트에 다이렉트로 연결하는 기법
- Find를 실행한 노드는 이후부터 루트 노드를 한번에 알 수 있다.
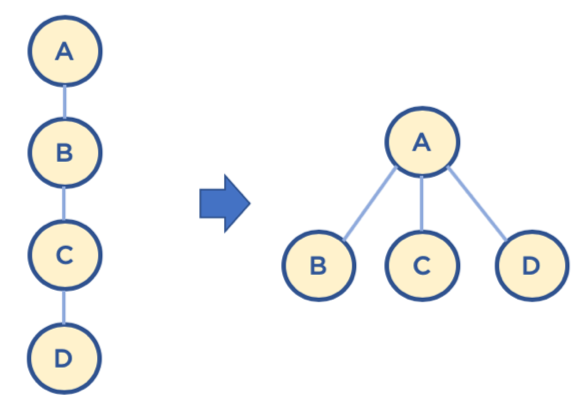
정리
union-by-rank 기법 사용 시 시간복잡도가 O(logN)으로 낮출 수 있다는 걸 확인했었는데
거기에 path compression 기법 사용 시 O(1)에 가깝게 줄일 수 있다고 한다. (수학적으로 증명된 사실)
즉, Union Find 알고리즘을 사용해서 사이클을 체크한다면 시간복잡도를 O(N)에서 O(1)로 낮출 수 있다는 걸 인지하면 된다.
크루스칼 알고리즘 코드 작성
graph = {
'vertices': ['A', 'B', 'C', 'D', 'E', 'F', 'G'],
'edges': [
(7, 'A', 'B'), # A와 연결된
(5, 'A', 'D'),
(7, 'B', 'A'), # B와 연결된
(8, 'B', 'C'),
(9, 'B', 'D'),
(7, 'B', 'E'),
(8, 'C', 'B'), # C와 연결된.. 이런식으로 각 정점마다 연결된 간선들을 작성
(5, 'C', 'E'),
(5, 'D', 'A'),
(9, 'D', 'B'),
(7, 'D', 'E'),
(6, 'D', 'F'),
(7, 'E', 'B'),
(5, 'E', 'C'),
(7, 'E', 'D'),
(8, 'E', 'F'),
(9, 'E', 'G'),
(6, 'F', 'D'),
(8, 'F', 'E'),
(11, 'F', 'G'),
(9, 'G', 'E'),
(11, 'G', 'F')
]
}
parent = {}
rank = {}
# * 부모 노드가 자기 자신인 것은 루트 노드
def find(node):
# path compression 기법
if parent[node] != node: # 현재 노드는 루트 노드가 아닐 경우
parent[node] = find(parent[node])
return parent[node]
def union(node_v, node_u):
# 1. 루트 노드의 랭크 값이 다를 때
# 2. 각 부분 집합의 루트 노드의 랭크 값이 동일할 때
root1 = find(node_v)
root2 = find(node_u)
# union-by-rank 기법
if rank[root1] > rank[root2]:
parent[root2] = root1
else:
parent[root1] = root2
if rank[root1] == rank[root2]:
rank[root2] += 1
def make_set(node): # 초기화 함수 -> 모든 노드를 각각의 분리된 집합으로. 즉, 자기 자신으로 루트 노드로
parent[node] = node
rank[node] = 0
def kruskal(graph):
mst = list()
# 1. 초기화
# 각각의 노드를 개별적 집합으로
for node in graph['vertices']:
make_set(node)
# 2. 간선 weight 기반 sorting
edges = graph['edges']
edges.sort()
# 3. 사이클 없는 간선만 연결
for edge in edges:
weight, node_v, node_u = edge
if find(node_v) != find(node_u): # find()를 통해 두 노드의 루트 노드가 다른지 확인
union(node_v, node_u) # union()을 통해 하나의 집합으로 합친다.
mst.append(edge)
return mst
result = kruskal(graph)
print(result)
# [(5, 'A', 'D'), (5, 'C', 'E'), (6, 'D', 'F'), (7, 'A', 'B'), (7, 'B', 'E'), (9, 'E', 'G')]
시간복잡도
크루스칼 알고리즘의 시간복잡도는 결론적으로 O(ElogE)이다.
아래 단계 중 2단계의 간선을 비용 기준으로 정렬하는 시간에 좌우된다. (즉, 정렬하는 시간이 가장 큼)

- 모든 정점을 독립적인 집합으로 만든다.
- 정점 개수 V 만큼 돌며 초기화시키므로 -> O(V)
- 모든 간선을 비용 기준으로 정렬 후, 비용이 작은 간선부터 양 끝의 두 정점을 비교한다.
- quick sort를 사용한다면 시간복잡도는 O(nlogn)이며,
n이 간선이므로 간선은 E(Edge)로 표현되기에 O(ElogE)이다.
- quick sort를 사용한다면 시간복잡도는 O(nlogn)이며,
- 두 정점의 최상위 정점을 확인한 후, 서로 다를 경우만 두 정점을 연결한다. (사이클이 생기지 않게)
- 간선(Edge)의 개수만큼 for문을 돌며 확인하기에 -> O(E)
- union-by-rank, path compression 기법 사용 시 시간복잡도가 상수값에 가까워진다. -> O(1)
이렇게 1~3번의 과정에 걸쳐 시간복잡도는 O(V) + O(ElogE) + O(E)가 되는데
O(V) < O(E) < O(ElogE) 순서로 커지므로 O(V)와 O(E)는 생략되어
전체적인 크루스칼 알고리즘의 시간복잡도는
quick sort를 썼을 때 sorting 시간복잡도와 동일한 O(ElogE)가 된다.
'자료구조알고리즘 > 이론' 카테고리의 다른 글
| 투 포인터(Two Pointers) - start~end, merge sort, prefix sum (0) | 2023.04.18 |
|---|---|
| 코딩테스트 관점에서의 시간복잡도 (0) | 2023.04.18 |
| 최소 신장 트리(Minimum Spanning Tree, MST) (0) | 2023.04.18 |
| 백트래킹(backtracking) (0) | 2023.04.16 |
| 그래프 - 최단 경로 알고리즘, 다익스트라 알고리즘 (0) | 2023.04.16 |

